
Um komplexe Strukturen in einer Datenbank abzubilden, sind eine Vielzahl an Verbindungen notwendig welche mit traditionellen Datenbanksystemen mithilfe von Fremdschlüsseln und Mapping Tabellen oft nur mit großem Aufwand abgebildet werden können. Durch die steigende Komplexität werden dadurch Abfragen sehr umständlich bzw. leidet meist auch die Performance darunter.
Wenn Daten sehr viele Beziehungen untereinander besitzen ist eine Graph Datenbank sehr gut geeignet. Microsoft SQL Server 2017 bietet die Möglichkeit in der gewohnten Datenbankumgebung Daten als Graph abzubilden.
Mithilfe eines Beispiels, welches Beziehungen zwischen Personen, Firmen und Produkten darstellt (siehe Abbildung Graph Beispiel) wird gezeigt wie Daten als Graph gespeichert werden können.

Ein Graph besteht aus Knoten (Objekte) und Kanten (Verbindungen). Um einen Knoten anzulegen, wird eine Tabelle erstellt und mit „AS NODE“ deklariert. Daten können dann wie gehabt mittels INSERT Statement eingefügt werden.

Der einzige Unterschied zu einer normalen Tabelle ist die zusätzliche Spalte mit welcher ein Tabelleneintrag in der ganzen Datenbank eindeutig referenziert werden kann.
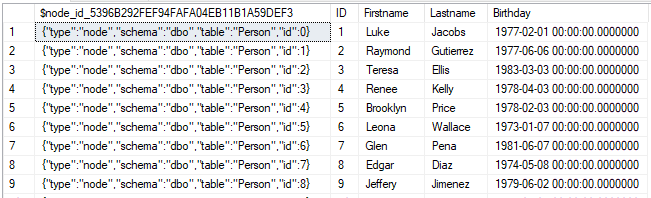
Auch eine Kante wird als Tabelle definiert. Dadurch können einer Verbindung noch zusätzliche Attribute zugewiesen werden. Um einen Wert in die Kantentabelle einzufügen, müssen der Ausgangsknoten, der Zielknoten und weitere Attribute (je nach Tabellendefinition) in einem Insert Statement angegeben werden. Hierbei ist der Typ der Knoten nicht beschränkt und es können z.B. Kaufrelationen von Firma/Produkt sowie Person/Produkt definiert werden.


Damit der SQL Server die Graph Tabellen von herkömmlichen Tabellen unterscheiden kann, werden bei Definition von Knoten und Kanten automatisch Metadaten in der System Tabelle abgespeichert.

Im SQL Server Management Studio werden Graph Tabellen in einem eigenen Ordner angezeigt.
Nachdem alle Knoten und Kanten erzeugt und mit Daten befüllt wurden, können nun Abfragen gestartet werden. Hierbei wird das MATCH Statement verwendet. Dieses wird mit Argumenten in der Form node-(edge)->node definiert. (https://docs.microsoft.com/en-us/sql/t-sql/queries/match-sql-graph?view=sql-server-2017). Als Beispiel können wir mittels der folgenden SQL Abfrage (Abbildung Zulieferer) alle zugelieferten Produkte mit den zugehörigen Firmen ausgeben.

Im MATCH Statement können mehrere Beziehungen mittels AND angegeben werden. Im abschließenden Beispiel werden alle Produktkäufe durch Empfehlung eines Freundes abgefragt. Wir nehmen eine Produktempfehlung bei einem Produktkauf einer Person an, bei der ein Freund dasselbe Produkt innerhalb der letzten drei Monate gekauft hat.

Anwendung BI
Die Graph Struktur lässt sich auch im BI Umfeld auf das Star Schema anwenden, um eine intuitive Sicht und Abfragemöglichkeiten auf die Daten bereitzustellen. Hier können die Fakten und Dimensionen als Nodes abgebildet werden.
Zusammenfassung
Eine Graph Datenbank bietet für gewisse Anwendungsfälle eine sehr vielversprechende Alternative zu traditionellen Datenbanksystemen. Die Integration in die bestehende SQL Umgebung ermöglicht auch ein relativ einfaches Migrieren von einer relationalen Datenbank zur Graph Datenbank. Natürlich gibt es aufgrund der Neuheit des Features noch einige Limitierungen (https://docs.microsoft.com/en-us/sql/t-sql/queries/match-sql-graph?view=sql-server-2017) welche jedoch hauptsächlich Optimierungen betreffen.
{kind=link}